UNIT series¶
UNIT¶
Unsupervised Image-to-Image Translation Networks (NIPS 2017) by Nvidia
Seperate the generator of GAN into encoder+decoder pairs, just like VAE.
Shared-latent space constraint implies the cycle-consistency constraint.
VAE + GAN + share weight of last layer of E1 and E2; also share the first layer of G1, G2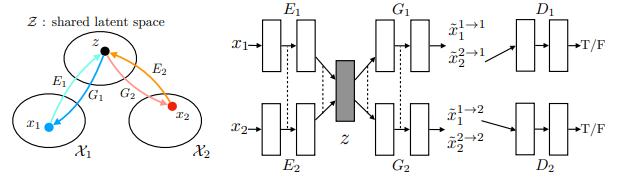
Cycle-consistency is not necessary for this task, however, preformance: proposed(UNIT-shared latent space + cycle-consistency) > cycleGAN > shared latent space (VAE-GAN)
comparing with cycleGAN, it learn shape better.
MUNIT¶
Multimodal Unsupervised Image-to-Image Translation (ECCV 2018)
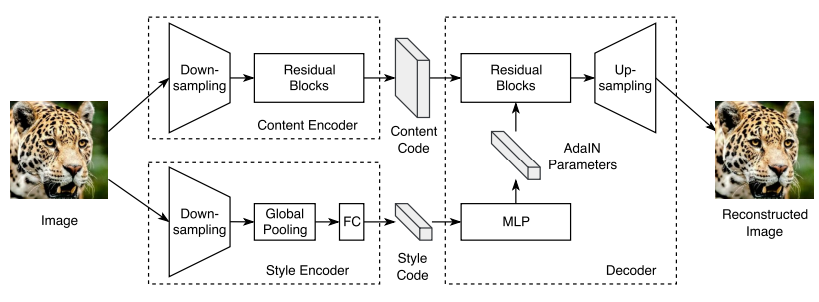
- seperate latent code into content code and style code, learn from swapping attribute code
- style is embedded in hidden layer of generator
DRIT¶
Diverse Image-to-Image Translation via Disentangled Representations (ECCV 2018)
Project | Pytorch 0.4.0
- concurrent works of MUNIT, style code in MUNIT~attribute code in DRIT
- keep weight sharing of UNIT
- add content adversarial loss to force content generator produce encoding that could not be distingished, same concept of Transfer Learning/DANN
DRIT++¶
- mode-seeking regularization for improving sample diversity Mode Seeking GAN
- add one-hot domain code
FUNIT¶
Few-Shot Unsupervised Image-to-Image Translation (ICCV 2019)
Project page | pyTorch | FUNIT Explained | GANimal Demo Video | Have fun with GANimal
TUNIT¶
Rethinking the Truly Unsupervised Image-to-Image Translation (2020) - Clova AI
pyTorch 1.1 |
reddit |
Twitter | youtube
Truly unsupervised: no any supervision, neither image-level(paired) or set-level (unpaired, domain)
similar to styleGAN? but styleGAN assume no domain as all while TUNIT assume dataset have dmoain, but it is unknown in training dataset. TUNIT learn to produce domain label via IIC clustering.