Attention Mechanism¶
Attention mechanism mainly used for NLP because of sequence model. CNN could also use self-attention, such as SAGAN.
Background¶
Before RNNsearch, sequence model is mostly implemented via RNN encoder-decoder. RNN could somehow handle sequence data, but it is heavely rely on the previous data (word for NLP), which is not flexible enough for language model.
seq2seq¶
Sequence to Sequence Learning with Neural Networks (NIPS 2014)
multilayered LSTM to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector.
RNNsearch¶
Neural Machine Translation by Jointly Learning to Align and Translate (2014~ICLR 2015)
In this paper, we conjecture that the use of a fixed-length vector is a bottleneck in improving the performance of this basic encoder-decoder architecture, and propose to extend this by allowing a model to automatically (soft-)search for parts of a source sentence that are relevant to predicting a target word, without having to form these parts as a hard segment explicitly.
Show, Attend and Tell¶
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (ICML 2015)
Generate word by word based on image
Transformer¶
Attention is all you need (NIPS 2017) - Google
google AI blog |
The Illustrated Transformer |
The Annotated Transformer - Harvard
Self-attention: sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. (For previous non-self attention, decoder consider the output of encoder. For self-attention, layer (both encoder or decoder) consider other repersentation within sequence.
Scaled Dot-Product Attention¶
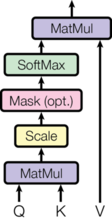
The input consists of queries \(Q\) and keys \(K\) of dimension \(d_k\), and values \(V\) of dimension \(d_v\) (channel of features)
$$ Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V $$
Multi-Head Attention¶
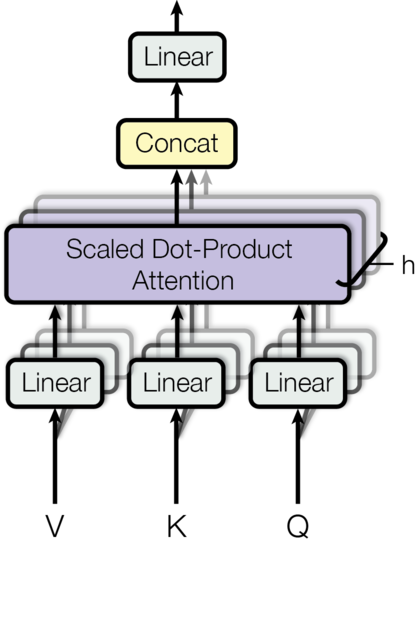
Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
Non-local Neural Networks¶
Non-local Neural Networks (CVPR 2018)
Caffe code
spacetime Non-local block
CBAM¶
CBAM: Convolutional block attention module(ECCV 2018)
Channel attention module (CAM)¶
Spatial Attention Module (SAM)¶
DNL¶
Disentangled Non-Local Neural Networks (ECCV 2020) / Disentangled self-attention models
bilibili explain (chinese) | text version | segmentation pyTorch | Object Detection pyTorch
Tranditional self-attention block can be splited into two terms, a whitened pairwise term and a unary term. The two tightly coupled terms hinders the learning of each. Disentangled non-local block decouple the two terms to facilitate learning for both terms.
denote \(q_i = W_qx_i, k_j=W_k x_j, \sigma(.)=softmax(.)\)
Standard non-local block (add within $\sigma$ ~ multiply)
\(w(x_i, x_j) = \sigma(q_i^Tk_j)=\sigma(\underbrace{(q_i-\mu_q)}_\text{pairwise}+\underbrace{\mu_q^T k_j}_\text{unary})\)
Disentangled non-local block (add unary term use decoupled \(W_m\) isntead of \(W_k\))
\(w^D(x_i, x_j)=\sigma(q_i^Tk_j)=\sigma(\underbrace{(q_i-\mu_q)}_\text{pairwise})+\sigma(\underbrace{W_m x_j}_\text{unary}))\)