Loss Functions¶
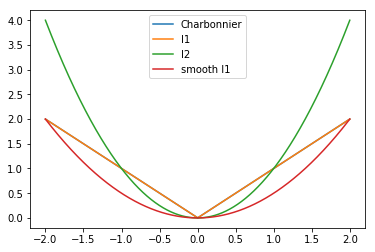
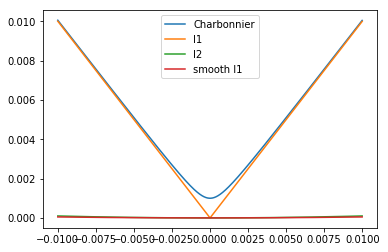
L2 & L1 Loss¶
L2 - MSE, Mean Square Error¶
Generally, L2 loss converge faster than l1. But it prone to over-smooth for image processing, hence l1 and its variants used for img2img more than l2.
L1 - MAE, Mean Absolute Error¶
** MAE seems better than MSE in image generation task, such as super-resolution
Smooth L1¶
Charbonnier Loss¶
LapSRN: Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks
Regression Loss Functions¶
MSE - Mean Squared Error¶
MAE - Mean Absolute Error¶
MSLE - Mean Squared Logarithmic Error¶
Cosine Proximity¶
Binary Classification Loss Functions¶
Binary Cross-Entropy¶
\(\hat{y}\) is prediction, y is ground truth
Hinge Loss¶
max-margin objective
Squared Hinge Loss¶
Multi-Class Classification Loss Functions¶
Multi-Class Cross-Entropy Loss¶
M: total number of class
Softmax Loss, Negative Logarithmic Likelihood, NLL¶
Cross Entropy Loss same as Log Softmax + NULL Probability of each class
\(\hat{y}\) is 1*M vector, the value of true class is 1, other value is 0, hence
, where c is the true label
Kullback Leibler Divergence Loss¶
=MLE (Max likelihood estimation) probability distribution
CNN Loss¶
Loss Functions for Image Restoration with Neural Networks
Content Loss¶
compare pixel by pixel Blurry results because Euclidean distance is minimized by averaging all plausible output e.g. MAE, MSE