Segmentation¶
pixel-wise labelling
干货 | 一文概览主要语义分割网络,FCN、UNet、SegNet、DeepLab 等等等等应有尽有
FCN (CVPR 2015)¶
Fully Convolutional Networks for Semantic Segmentation
final output low-resolution feature map(heatmap) as segmentation, upsampling with deconvolution
backbone VGG16
SegNet (CVPR 2015)¶
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation Project unpooling: the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling
Mask R-CNN (ICCV 2017)¶
Mask R-CNN
extends Faster R-CNN by adding a branch for predicting segmentation masks on each Region of Interest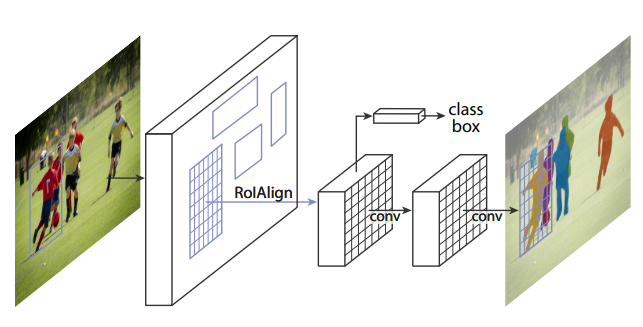
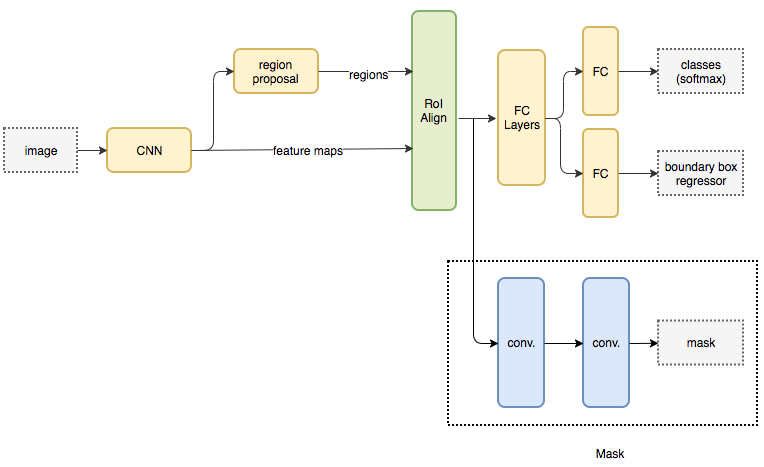
code: facebookresearch/Detectron
DeepLab¶
DeepLab v1 (ICLR 2015)¶
Semantic Image Segmentation with deep convolutional nets and fully connected CRFs
- Dilated Convolution, aka Atrous Convolution
- CRF post-process
DeepLab v2 (TPAMI 2017)¶
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Atrous Spatial Pyramid Pooling, ASPP
DeepLab v3 (2017)¶
Rethinking Atrous Convolution for Semantic Image Segmentation
- MultiGrid
- Image-level feature
PSPNet (CVPR 2017)¶
Pyramid Scene Parsing Network
Some said that it is difficult to re-product its result.
RefineNet (CVPR 2017)¶
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
provides multiple paths over which information from different resolutions and via potentially long-range connections
Multi-Path Refinement¶
divide pre-trained ResNet into 4 blocks and employ a 4-cascaed architecture with 4 RefineNet units.
Residual Conv Unit + Multi-resolution Fusion¶
Chained residual pooling¶
ICNet (ECCV 2018)¶
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
real-time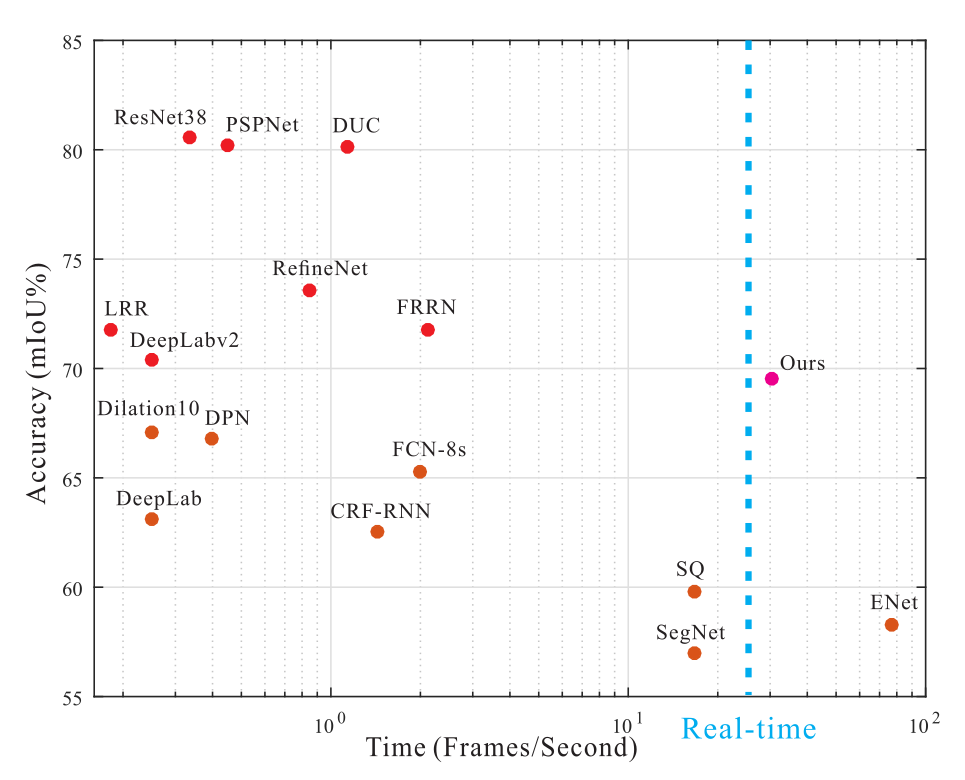 based on PSPNet
based on PSPNet
Cascade Feature Fusion, CFF¶
DANet¶
Dual attention network for scene segmentation (CVPR 2019)
pyTorch 1.4.0
integrate local features with their global dependencies based on the self-attention mechanism.
PAM¶
The position attention module selectively aggregates the feature at each position by a weighted sum of the features at all positions. Similar features would be related to each other regardless of their distances.
CAM¶
Meanwhile, the channel attention module selectively emphasizes interdependent channel maps by integrating associated features among all channel maps.