Light-Weight Models¶
Addition: The computation of below model reduced, but the number of layers might be increased. It is faster on CPU, but might not faster on GPU because of bandwidth limitation. See discussion: 为什么 MobileNet、ShuffleNet 在理论上速度很快,工程上并没有特别大的提升?
MobileNet v1¶
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications by Google
Depthwise Separable Convolution¶
seperate general convolution into 2 part: depthwise + pointwise
- depthwise: compute within each channel
- pointwise: 1x1 convolution on depthwise result i.e. drop cross-channel and cross-point connections Compression of Depthwise Separable Convolution
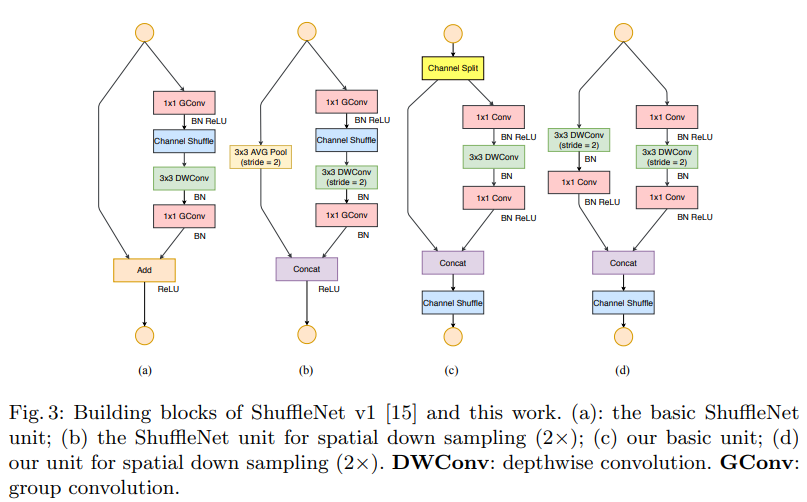
ShuffleNet v1 (CVPR 2018)¶
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices by face++
concurrent work of [Interleaved Group Convolutions for Deep Neural Networks]
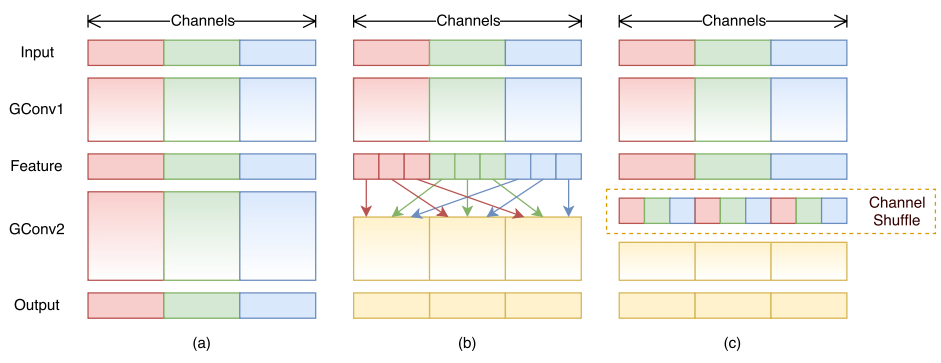
Group Convolution and Channel Shuffle¶
Seperate channels into different groups, convolution run within groups. Then channel shuffle the output of groups output.
MobileNet v2 (CVPR 2018)¶
MobileNetV2: Inverted Residuals and Linear Bottlenecks by Google
tensorflow code | blog
Inverted residual with linear bottleneck¶
shortcut connections between the bottlenecks
ShuffleNet v2 (ECCV 2018)¶
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design by face++
papers with code
Channel split¶
Excessive group convolution increases memmory access cost (MAC). Hence, use simple channel split instead of group convolution