image-to-image¶
pix2pix (CVPR 2017)¶
Image-to-Image Translation with Conditional Adversarial Networks by Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
https://phillipi.github.io/pix2pix/ |
Image-to-Image Demo
based on conditional GAN, with image as conditional&noise input dataset: paired image (supervised), e.g. segmentation/edge/map -> real photo, real photo → map
discriminator: PatchGAN which also take conditional as pairs
dataset: paired image (supervised), e.g. segmentation/edge/map -> real photo, real photo → map
discriminator: PatchGAN which also take conditional as pairs
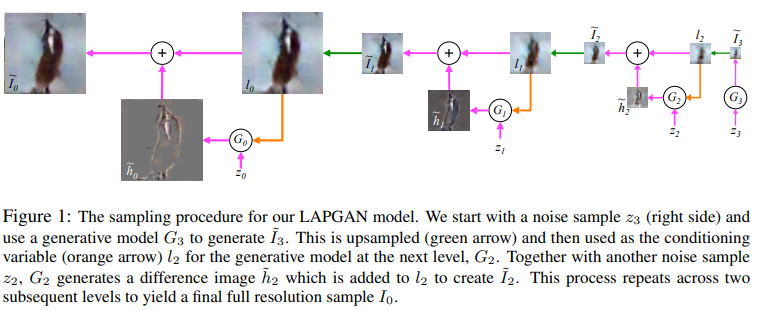
LAPGAN (NIPS 2015)¶
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
aim for high-resolution image via using low-resolution image as condition, similar to residual learning
In this paper we introduce a generative parametric model capable of producing high quality samples of natural images. Our approach uses a cascade of convolutional networks within a Laplacian pyramid framework to generate images in a coarse-to-fine fashion. Note: Could I consider it as GAN plus residual+GAN based super-resolution?
DTN (ICLR 2017)¶
Unsupervised Cross-Domain Image Generation
Domain Transfer Network(DTN) with Identity Loss.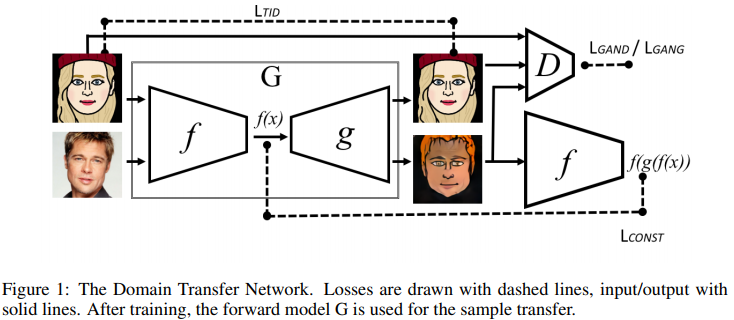
Identity Loss¶
first proposed in Equation 6 of this paper
The generator trained with this loss will often be more conservative for unknown content. – from CycleGAN FAQ
Two-Way GANs¶
Two-Way GANs
Could use unpaired datasets
Progressive GAN (ICLR 2018)¶
Progressive Growing of GANs for Improved Quality, Stability, and Variation by Nvidia
Official TensorFlow implementation | PyTorch implenetation (unofficial) | PyTorch/hub
Growing¶
resize + w * conv, increase weighting of convolution to fade smoothly
fully integrate previous learning result into bigger model
Normalization¶
Pixelwise Feature Vector Normalization in generator
Result¶
Compare with LAPGAN¶
Progressive GAN merge the small model into large model. In inference step, Progressive GAN take features as input, LAPGAN take low-resolution image as input
pix2pixHD (CVPR 2018)¶
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs by Nvidia + author of pix2pix
Project
We present a new method for synthesizing high-resolution photo-realistic images from semantic label maps using conditional generative adversarial networks (conditional GANs). Conditional GANs have enabled a variety of applications, but the results are often limited to low-resolution and still far from realistic. In this work, we generate 2048x1024 visually appealing results with a novel adversarial loss, as well as new multi-scale generator and discriminator architectures. Furthermore, we extend our framework to interactive visual manipulation with two additional features. First, we incorporate object instance segmentation information, which enables object manipulations such as removing/adding objects and changing the object category. Second, we propose a method to generate diverse results given the same input, allowing users to edit the object appearance interactively. Human opinion studies demonstrate that our method significantly outperforms existing methods, advancing both the quality and the resolution of deep image synthesis and editing.
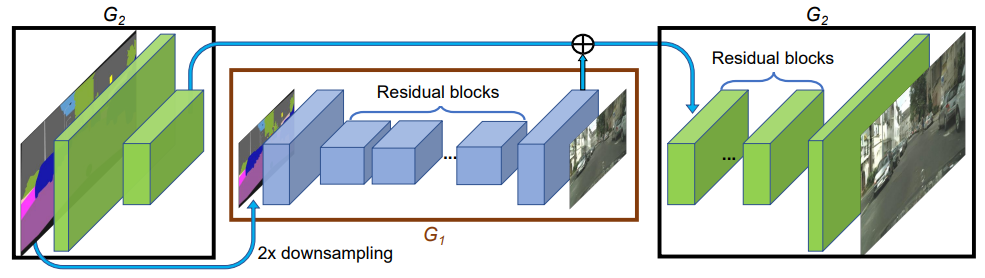
Coarse2fine Generator¶
Compare with Progressive GAN¶
- The main idea of both 2 paper is grow the GAN after training low-resolution. Training small generator first, then use a bigger generator include the small generator.
- pix2pixHD is supervised/conditional while Progressive GAN is un-supervised. pix2pixHD have a encoder in generator while Progressive GAN start with latent input.
- pix2pixHD is handle low-resolution image feature as residual. Progressive GAN fade-out the previous small model and let the big model continus learning the weight.
- When inference with final model, pix2pixHD input high resolution input image + resized low resolution input image(s). Progressive GAN input size remain (latent random noise).
Question: What if growing network like Progressive GAN (fade) instead of residual for conditional GAN? Sadly the requirement of training Progressive GAN is high (8 Tesla V100 ;_;)
vid2vid (NIPS 2018)¶
(put in this section because I consider video as sequence of images) Video-to-Video Synthesis (Arxiv) | Video-to-Video Synthesis | github - by Nvidia (Includes works of pix2pixHD and SPADE)
Transferring GANs (ECCV 2018)¶
Spectral Regularization (CVPR 2020)¶
Generative convolutional deep neural networks, e.g. popular GAN architectures, are relying on convolution based up-sampling methods to produce non-scalar outputs like images or video sequences. In this paper, we show that common up-sampling methods, i.e. known as upconvolution or transposed convolution, are causing the inability of such models to reproduce spectral distributions of natural training data correctly. This effect is independent of the underlying architecture and we show that it can be used to easily detect generated data like deepfakes with up to 100% accuracy on public benchmarks. To overcome this drawback of current generative models, we propose to add a novel spectral regularization term to the training optimization objective. We show that this approach not only allows to train spectral consistent GANs that are avoiding high frequency errors. Also, we show that a correct approximation of the frequency spectrum has positive effects on the training stability and output quality of generative networks.