Normalization¶
PS: usually use before activication
Local Response Normalization¶
LRN from AlexNet
sum runs over n “adjacent” kernel maps at the same spatial position, and N is the total number of kernels in the layer. The ordering of the kernel maps is of course arbitrary and determined before training begins. This sort of response normalization implements a form of lateral inhibition inspired by the type found in real neurons, creating competition for big activities amongst neuron outputs computed using different kernels.
In later development, it is claimed that LRN is not useful.
Pixelwise Feature Vector Normalization (ICLR 2018)¶
from Progressive GAN variant of LRN with all channels, i.e. n=N
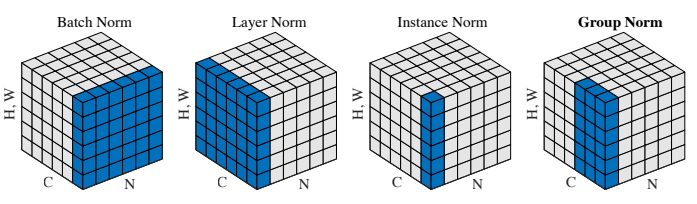
Batch Normalization¶
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (ICML 2015)
normalize x based on value over all values within same mini-batch with mean and variance
learnable parameters: scale and bias \(\gamma, \beta\)
For Prediction, use population mean and population variance calucated during training.
The effectiveness diminishes when the training minibatches are small.
Why BatchNorm works?¶
Original paper said BatchNorm reduce Internal Covariate Shift: the change in the distribution of network activations due to the change in network parameters during training.
How Does Batch Normalization Help Optimization? (NIPS 2018) demonstrate is NOT Internal covariate shift and suggest it makes the optimization landscape significantly smoother.
High Frequency Component Helps Explain the Generalization of Convolutional Neural Networks (CVPR 2020) suggested that batchNorm pick more high frequence component, which reduce robustness. It is probably why Batch Normalization is a Cause of Adversarial Vulnerability (ICML 2019).
Layer Normalization¶
Layer Normalization (NIPS 2016)
no batch size required
for shared weight model, e.g. RNN, CNN(but not good for CNN)
might reduce the representivity of model
Weight Normalization¶
- not relay on batch
- less noise
- less computation since not saving avg and variance of batch data
disadv:
- need good initialization, high dependency of input data
- unstable on training
Instance normalization¶
Instance Normalization: The Missing Ingredient for Fast Stylization (2016)
like batch norm with 1 batch size (still normalize though heightxwidth)
SELU (NIPS 2017)¶
Group Normalization¶
Conditional BatchNorm¶
Modulating early visual processing by language (NIPS 2017)
pytorch | guessWhat?!
\(\gamma, \beta\) learnt from one-hidden-layer MLP rely on input
used in cGAN with projection discriminator and SAGAN
Conditional Instance Normalizatoin¶
AdaIN¶
Stands for Adaptive Instance Normalization
Arbitrary style transfer in real-time with adaptive instance normalization (ICCV 2017)
scale with output domain distribution
Batch Renormalization¶
Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models (NIPS 2017) by Google
data in batch cannot cover the real data distribution -> batchNorm perform badly
using moving avg mean and SD -> the gradient optimization and the normalization to counteract each other -> model blow up
novel re-normalization apply on x (before scaling)
mean and SD of batch: \(\mu_B \sigma_B \)
moving avg (larger than 1 batch) of mean and SD: \(\mu \sigma \)
- have higher improvement when the batch small and data distribution diverse, not easy to over-fit 如何评价batch renormalization? - 汪汪的回答 - 知乎
SPADE¶
stands for SPatially-Adaptive (DE)normalization
Semantic Image Synthesis with Spatially-Adaptive Normalization (CVPR 2019) by Nvidia solving issue: semantic information washed away through stacks of convolution, normalization, and nonlinearity layers
similar to batchNorm, activation is normalized in the channelwise manner, and then modulated with learned \(\gamma, \beta\)
solving issue: semantic information washed away through stacks of convolution, normalization, and nonlinearity layers
similar to batchNorm, activation is normalized in the channelwise manner, and then modulated with learned \(\gamma, \beta\)
Unlike prior conditional normalization, \(\gamma, \beta\) are not vectors, but tensors with spatial dimensions
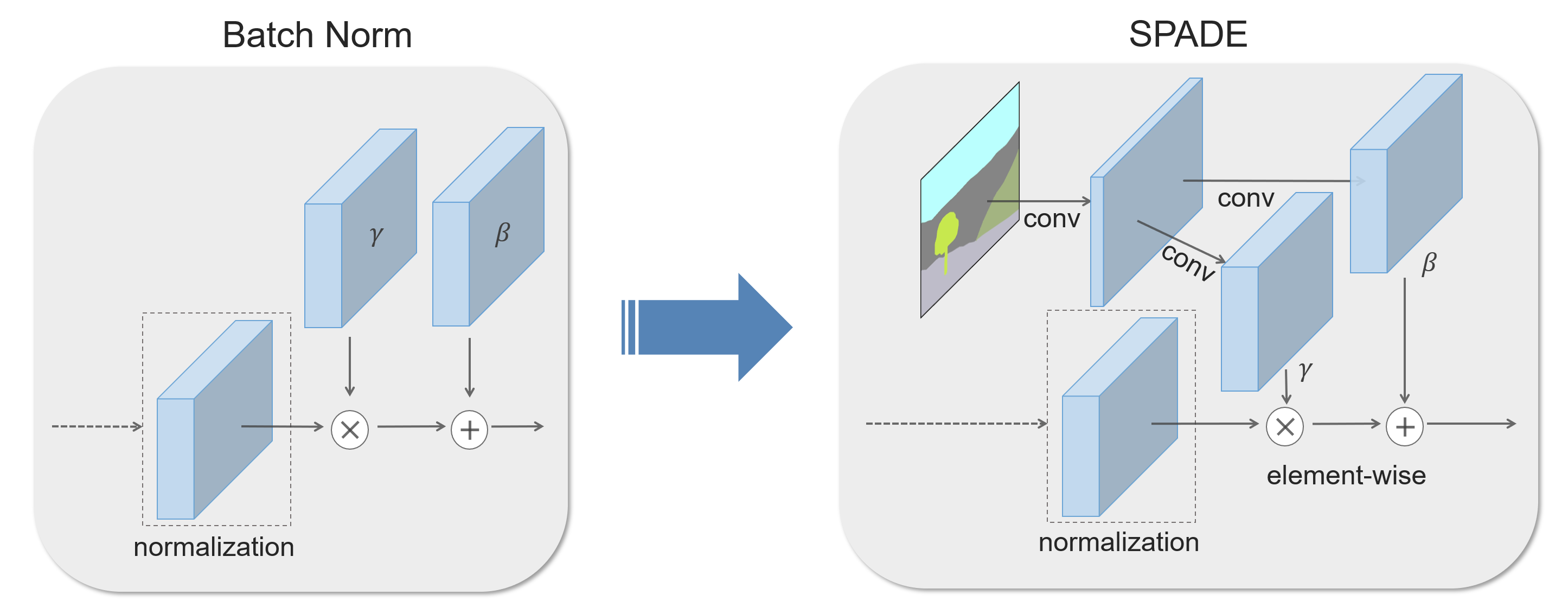
using the input layout for modulating the activations in normalization layers through a spatially-adaptive, learned transformation (two-layers convolutional network).
Summary and use cases¶
| usable situation | unsuitable application | example model(s) | |
|---|---|---|---|
| LRN | AlexNet, ProgressiveGAN(variant n=N with all channels) | ||
| BatchNorm | batch reflect real data distribution | RNN,small batch size,patch based,WGAN-GP | UNet |
| LayerNorm | no batch sized required, RNN | ||
| WeightNorm | no batch sized required | WDSR | |
| InstanceNorm | instance specified, e.g. img2img | classification | DeblurGAN |
| SELU | feed-forward network (FNNs) | CNN, RNN | audio, features based model |
| GroupNorm | |||
| BatchReNorm | any BatchNorm with small batch size | OCR | |
| Conditional BatchNorm | conditional GAN | unconditional | SAGAN |
| AdaIN | Style Transfer | StyleGAN, U-GAT-IT, FUNIT | |
| SPADE | conditional CNN GAN | unconditional | GauGAN |