UNIT series¶
UNIT (NIPS 2017)¶
Unsupervised Image-to-Image Translation Networks by Nvidia
Seperate the generator of GAN into encoder+decoder pairs, just like VAE.
Shared-latent space constraint implies the cycle-consistency constraint.
VAE + GAN + share weight of last layer of E1 and E2; also share the first layer of G1, G2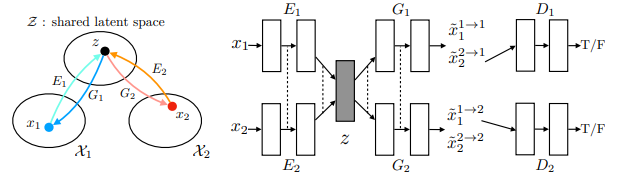
Cycle-consistency is not necessary for this task, however, preformance: proposed(UNIT-shared latent space + cycle-consistency) > cycleGAN > shared latent space (VAE-GAN)
comparing with cycleGAN, it learn shape better.
MUNIT (ECCV 2018)¶
Multimodal Unsupervised Image-to-Image Translation
- seperate latent code into content code and style code, learn from swapping attribute code
- style is embedded in hidden layer of generator
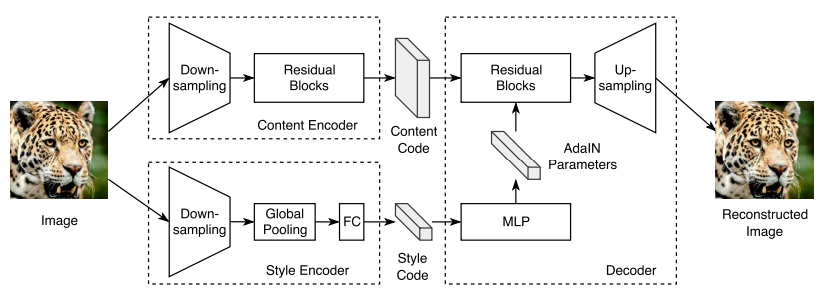
DRIT (ECCV 2018)¶
Diverse Image-to-Image Translation via Disentangled Representations
Project | Pytorch 0.4.0
- concurrent works of MUNIT, style code in MUNIT~attribute code in DRIT
- keep weight sharing of UNIT
- add content adversarial loss to force content generator produce encoding that could not be distingished, same concept of Transfer Learning/DANN
DRIT++ (IJCV Journal extension for ECCV 2018)¶
DRIT++: Diverse Image-to-Image Translation via Disentangled Representations
- mode-seeking regularization for improving sample diversity Mode Seeking GAN
- add one-hot domain code