Pose-to-Body¶
also see Video Synthesis
Types¶
A. Train a uniform generator for different videos. Reference appearance frame and pose/motion are input as condition during inference.
B. Train a generator on frames of same video. The appearance is encoded in the model. Only pose/motion input is required during inference.
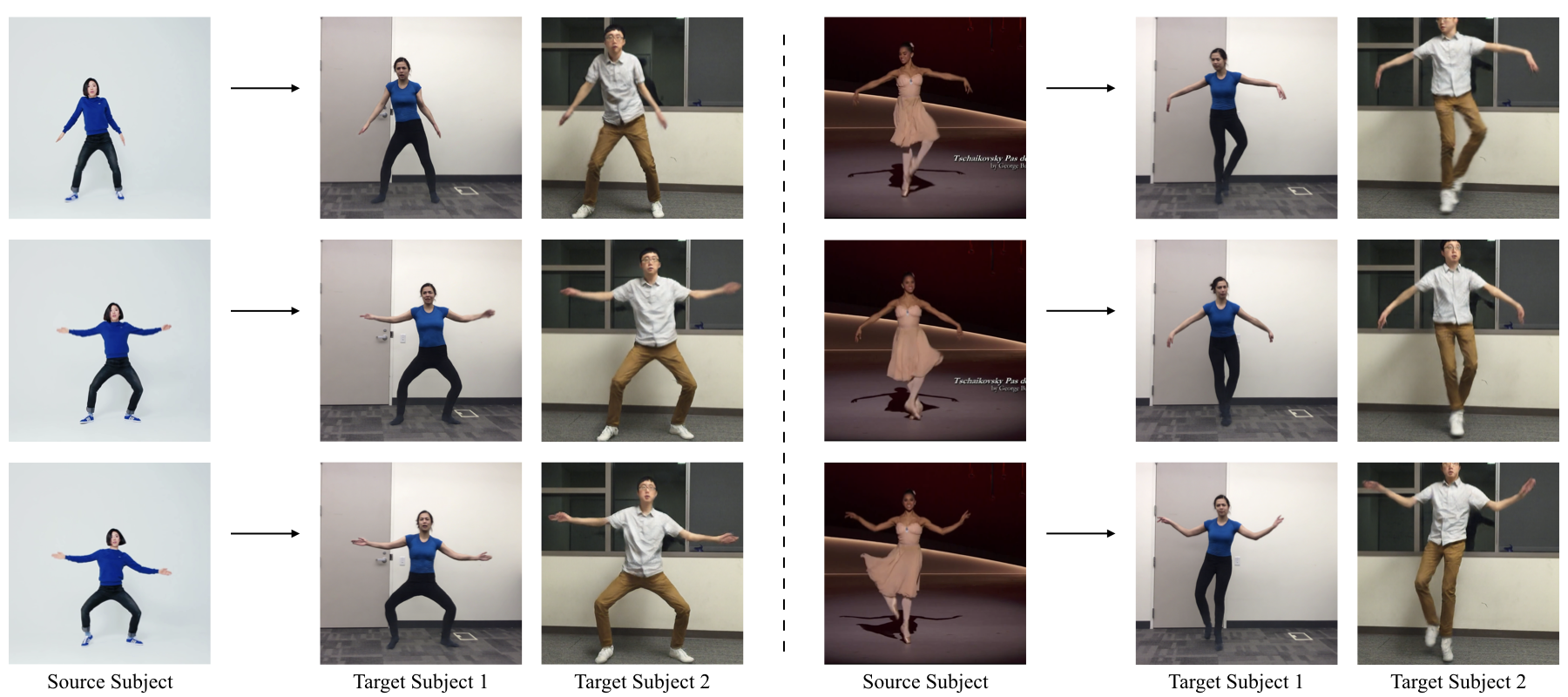
Generally, type B seems give nicer result with less artifact, but need to re-train a new model for each traget person. Used in motion re-target papers.
- vid2vid
- Deep Video-Based Performance Cloning
- Everybody Dance Now
Pose Guided Person Image Generation¶
Pose Guided Person Image Generation (NIPS 2017)
python 2.7 + tensorflow-gpu 1.4.1
PoseWarp¶
Synthesizing images of humans in unseen poses (CVPR 2018)
CVPR 2018 Oral | Keras
Source Image Segmentation + Spatial Transformation + Foreground Synthesis + Background Synthesis
VUNet¶
A Variational U-Net for Conditional Appearance and Shape Generation (CVPR 2018)
Project | tensorflow >= 1.3.0

Pose Guided Human Video Generation¶
vid2vid¶

Deep Video-Based Performance Cloning¶
Progressive Pose Attention Transfer for Person Image Generation¶
Progressive Pose Attention Transfer for Person Image Generation (CVPR 2019)
PyTorch 0.3.1 or 1.0








Everybody Dance Now¶
EDN (ICCV 2019) skeleton-to-rendering part