CNN Models¶
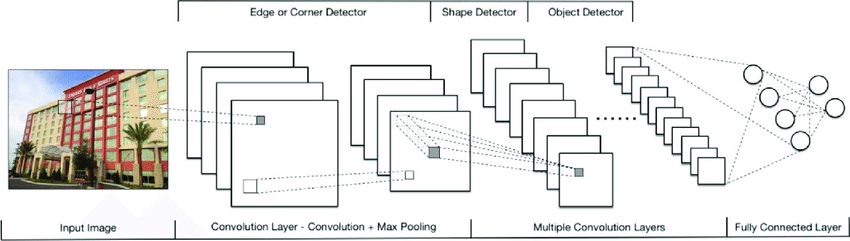
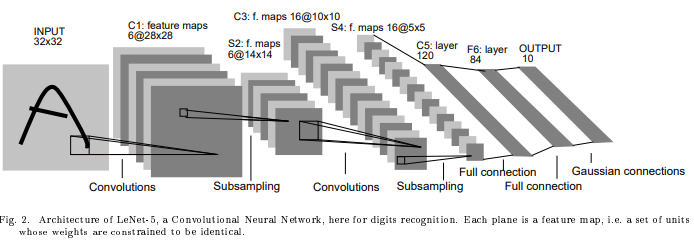
AlexNet¶
ImageNet Classification with Deep Convolutional Neural Networks (NIPS 2012)
ReLu: solve vanishing gradient, training process faster
dropout: solve overfitting
Local Response Normalization - Normalization/LRN
VGG (ICLR 2014)¶
Very Deep Convolutional Networks for Large-Scale Image Recognition
replace large kernel by mult. small kernels
receptive field of 3x3+3x3 = 5x5
parameters 18 < 25
the network loss to inception, but the pretrained network is useful for image feature embedding
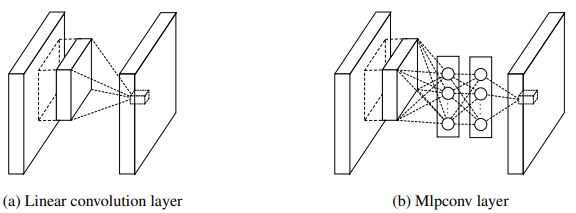
STN (CVPR 2015)¶
Spatial Transformer Networks from DeepMind
learn spatial transformation from data in a deep learning framework. It warps the feature map via a global parametric transformation such as affine transformation
- Localisation net: predict transform parameters \( \theta \)
- Parameterised Sampling Grid: apply \( \theta \)
- Differentiable Image Sampling: apply sampling kernel which defines the image interpolation (e.g. bilinear)
Backpropagation: differentiate through the sampling mechanism.
r/what_happened_to_spatial_transformers seems easily collapsed
alternative: Deformable Convolution
U-Net (MICCAI 2015)¶
U-Net: Convolutional Networks for Biomedical Image Segmentation
An encoder-decoder architecture with skip-connections that forward the output of encoder layer directly to the input of the corresponding decoder layer through channel-wise concatenation.

ResNet (CVPR 2016)¶
Residual Network
Deep Residual Learning for Image Recognition
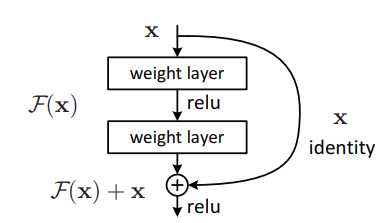 preserve information, learning details
also solve 1. vanishing gradient
2. Degradation problem
preserve information, learning details
also solve 1. vanishing gradient
2. Degradation problem
Degradation problem¶
deeper network give higher train & test error than shallover network
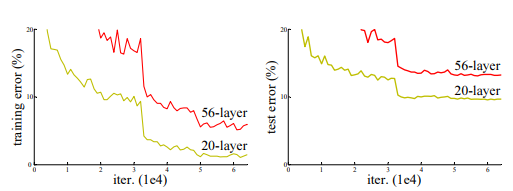
ResNet vs U-Net¶
Both are method to skip connection
| ResNet / residual block | U-Net |
|---|---|
| short connection usually, very general | long connection |
| element-wise sum | concatenation |
| channel remain the same | channel increase when concatentation (feature duplicated) |
| keep w,h/ resolution | down-scaling in-between, upscale before concatentation |
Deconvolution¶
The naming of “deconvolution”/ “transposed convolution” is quite unclear, so I put it together for direct comparison.
- Upsampling, image generation
- Covolutional sparse coding, unspervised learning
- Visualization
ref: 谭旭: 如何理解深度学习中的deconvolution networks? - 知乎
Upsampling, image generation¶
Also called Fractionally strided convolutions
inidivual, not related to previous convolution
 more animations
more animations
Upsampling with deconvolution might lead to checkerboard artifact because of strides, pixelShuffle could fully utils all weights hence and solve this issue
Paper using deconvolution for upsampling:
- autoencoder
- “deconvolutional” generator from GAN (NIPS 2014)
- segmentation/FCN: Fully convolutional networks for semantic segmentation (CVPR 2015)
- DeconvNet: Learning deconvolution network for semantic segmentation (ICCV 2015)
unpooling: use the max locations of the encoder feature maps (pooling indices) to perform non-linear upsampling in the decoder network
deconvolution: convolution transpose
Covolutional sparse coding, unspervised learning¶
Train an autoencoder first, then use deconvolution to extract features from trained weights.
- Deconvolutional networks (CVPR 2010) - Matthew D. Zeiler
- [Adaptive deconvolutional networks for mid and high level feature learning (ICCV 2011)] - Matthew D. Zeiler
Visualization¶
Compute transpose of trained convolutional layer, to visualize the pixels that activate specified feature (channel in high-level layer), understand the approximate purpose of each convolution filter
- FZNet: Visualizing and Understanding Convolutional Networks (ECCV 2013) - Matthew D. Zeiler
PixelShuffle (CVPR 2016)¶
Fusing global feature¶
Let there be Color! (2016)
fusion layer
usually used for global feature
CAM (CVPR 2016)¶
DenseNet (CVPR 2017)¶
Densely Connected Convolutional Networks
Connect to previous layer with concatenation (rather than sum)
Many said it is not quite useful and using residual instead.
From visualization result, seems low-layer feature really useful for high layer. (Maybe the middle level layer will learn middle level information without storing low level info with DenseNet architecture.)
Memory-Efficient Implementation of DenseNets¶
DenseNet less parameters but require more memory because of implementation of concatenation. Could be optimizated via shared memory.
Ablation Experiments of other paper:¶
Removing the DenseNet connections results in higher training error but lower validation errors when the model is trained on FlyingChairs. However, after the model is fine-tuned on FlyingThings3D, DenseNet leads to lower errors. PWC-Net-small further reduces this by an additional 2 times via dropping DenseNet connections and is more suitable for memorylimited applications
CapsuleNet (2017)¶
Dynamic Routing Between Capsules For dynamic routing vector to vector instead of scalar to scalar
Deformable Convolution¶
DCNv1 (ICCV 2017)¶
Deformable Convolutional Networks from MSRA
[Original: Caffe on Window-not released] | MXnet | pyTorch:mmdetection 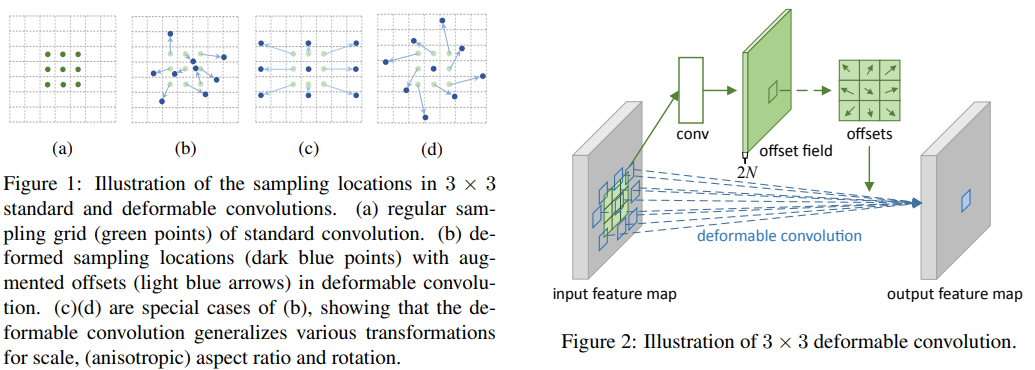
The backpropagation of \(\delta p_k\) is similar to STN. comparing to STN, Deformable ConvNet samples the feature map in a local and dense manner
DCNv2 (CVPR 2019)¶
Deformable ConvNets v2: More Deformable, Better Results from MSRA
Stacking More Deformable Conv Layers
modulated deformable convolution
\[y(p)=\sum^K_{k=1}w_k \dot x(p+p_k+\delta p_k) \dot \delta m_k\]output 3K channels, where first 2K correspond to \( {\delta p_k}^K_{k=1} \), remaining K channels further fed to sigmoid to obtain \( \{\delta m_k\}^K_{k=1} \)
R-CNN Feature Mimicking (knowledge distillation) to Faster R-CNN
Some said the detection result of DCNv1, v2 is not SOTA. However, the novelty is very high and it could be applied to many other img2img tasks with good result, such as [EDVR]. From the experience of training EDVR, training with DCN is unstable.
Deep Layer Aggregation, DLA (CVPR 2018)¶
Deep Layer Aggregation
image classification network with hierarchical skip connections